FalconFS: Trading Rename Performance for Single-Hop Operations at Scale
The Challenge: Metadata at AI Scale
Production AI workloads now span 100+ billion small files accessed in random patterns during training. This unprecedented scale exposes a fundamental limitation in distributed filesystem design: current DFS architectures cannot simultaneously achieve metadata locality and scalability - directory partitioning bottlenecks on hot paths while hash partitioning scatters related metadata across all servers. Traditional systems are trapped: they promise to make every operation fast, including rarely-used ones like rename. However, AI workloads exhibit a striking characteristic: rename operations, while critical for general computing, virtually never occur during model training. This insight opens a new design space: what if we explicitly sacrifice rename performance to achieve both scalability AND locality for all other operations? FalconFS explores this tradeoff by optimizing aggressively for reads and creates while accepting poor rename performance.
How FalconFS Achieves One-Hop Operations at Scale
The Architecture
FalconFS consists of three core components: MNodes for managing metadata, file stores for handling data blocks, and clients for coordinating operations.
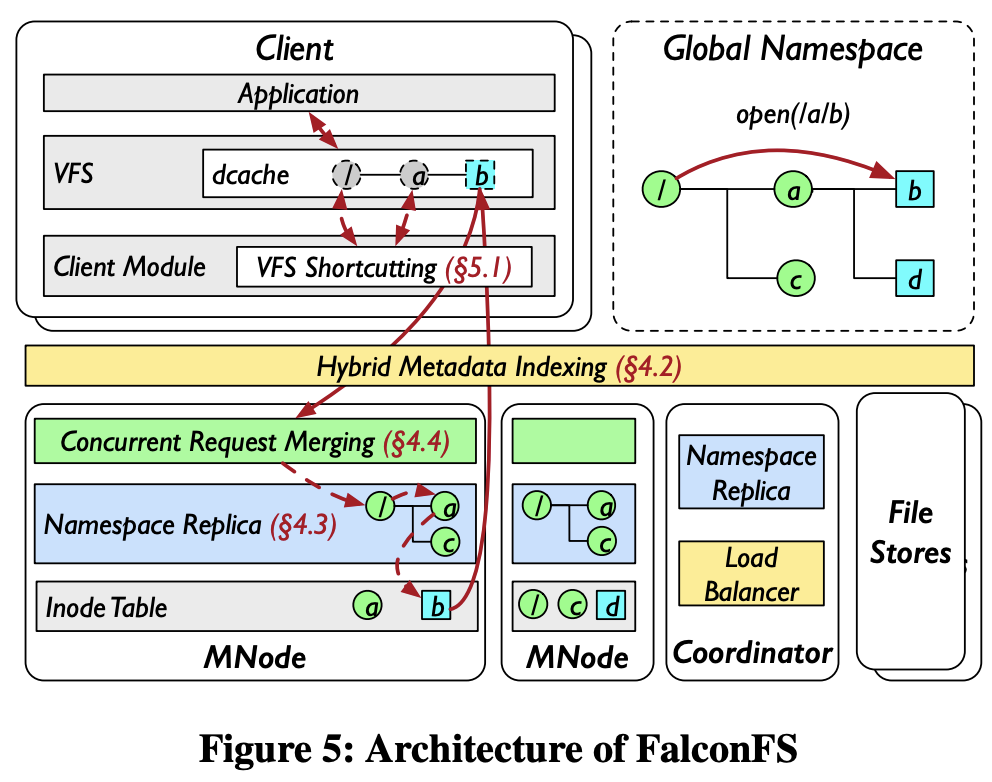

The Core Innovation: Name-Based Routing
Traditional distributed filesystems route requests based on full paths. For example, accessing /data/models/checkpoint.pt might involve:
- Contacting Server-1, which owns
/data. - Then Server-3, which owns
/data/models. - Finally, Server-7, which owns the file itself.
In contrast, FalconFS eliminates path-based routing entirely. It routes requests solely based on the filename. For instance, hash("checkpoint.pt") -> Server-7. Whether the file is at /data/checkpoint.pt or /backups/old/v2/checkpoint.pt, it always lives on Server-7. One hash, one hop, and the file is found.
Making Path Resolution Work
But wait - how does Server-7 verify the client has permission to access /data/models/checkpoint.pt if it doesn't know about those directories?
FalconFS solves this with lazy directory replication. Each metadata server (MNode) maintains a cache of directory entries (dentries) it needs. Initial request: /data/models/checkpoint.pt:
- Client hashes
checkpoint.ptand routes to MNode-7. - MNode-7 checks its cache for
/data/models/permissions. - Cache miss. MNode-7 fetches directory info from owners.
- MNode-7 caches this for future requests.
- Subsequent operations complete entirely on MNode-7.
After warmup, each MNode has a complete view of the directory paths leading to its files. No cross-server communication needed.
Boosting Read/Create Performance and Scalability
- Performance: As previously mentioned, after cache warmup, each MNode maintains complete path information for files it serves. Any read or create operation completes in a single network hop directly to the owner MNode.
- Scalability: The filename-based partitioning ensures that as long as filenames are reasonably distributed (which is typical in AI datasets with millions of unique files), requests naturally load-balance across MNodes. Adding more MNodes directly increases the system's capacity to handle concurrent requests, providing near-linear scalability for read operations.
Maintaining Correctness Guarantees
While optimizing for performance and scalability, FalconFS maintains full correctness guarantees: linearizability, serializability, and atomicity. This is crucial - optimizations without correctness have no value.
Serializability Through Two-Phase Locking
FalconFS ensures serializability using hierarchical two-phase locking:
- MNode-level explicit locks: Traditional in-memory locks (e.g.,
std::shared_lock) that protect local operations within each MNode. - Coordinator-level implicit locks: An MSI-style (Modified, Shared, Invalid) coherence protocol (similar to a memory coherence protocol) that maintains consistency across MNodes without explicit lock requests.
- Shared: Normal state where dentries are replicated across MNodes for reading.
- Modified: Exclusive state for the owner MNode to modify a dentry. When needed, the owner revokes all S states from other MNodes and transitions to M state.
- Invalid: State of non-owner MNodes after the owner acquires M state for modification.
For an operation on /data/models/checkpoint.pt:
- First, MNode-7 acquires local locks on
/,/data,/data/models, and/data/models/checkpoint.pt(root to leaf order). - Then, MNode-7 verifies all cached dentries remain in valid states (S or M) and blocks any incoming invalidation requests until operation completes. This is equivalent to acquiring coordinator-level locks - but done implicitly through the coherence protocol. No explicit coordinator interaction occurs, preserving the one-hop architecture.
- Finally, all locks are released in reverse order once the operation completes.
This strict ordering prevents deadlocks while ensuring serializable execution.
Linearizability Through Clear Linearization Points
Linearizability is guaranteed because:
- The linearization point for each request is clearly defined as the moment it acquires its final lock.
- This lock acquisition always occurs within the request's real-time bounds - after the client initiates the operation and before any response is returned.
- The 2PL protocol enforces a consistent ordering of conflicting operations. Once a request acquires its locks, no conflicting request can proceed until those locks are released. This ensures a globally consistent total order that respects the partial orderings of conflicting requests.
Atomicity via Appropriate Protocols
FalconFS handles atomicity based on operation scope:
- Single-MNode operations (file creation, writes): The owning MNode ensures atomicity through local transactions. No coordination overhead required.
- Multi-MNode operations (rename): The coordinator uses two-phase commit to ensure atomicity across servers.
This selective approach maintains strong consistency while minimizing coordination - most operations require no distributed transactions.
Comparison with Similar Approaches
FalconFS isn't alone in trading rename performance for better performance and scalability of other operations - LocoFS shares this key insight that making renames expensive unlocks both horizontal scalability and single-hop performance for common operations, though implements it differently.
- Directory ownership: LocoFS centralizes all directories on one server; FalconFS distributes them across all servers.
- Cache coherence: LocoFS uses time-based leases; FalconFS uses MSI-style state transitions.