Delta Lake
概述
大数据领域掀起了数据湖浪潮,AWS 、Azure 、腾讯、阿里等云计算厂商都推出了数据湖解决方案。数据湖使用对象存储替代传统 HDFS 作为存储层,获得了低成本、开放等优势。Databricks 融合数据仓库和数据湖,提出了 Lakehouse 的概念,并依次实现了 Delta Lake 。本文会分析 Lakehouse 和 Delta Lake ,探寻业界动态。
笔者认为数据的开放性和对数据的掌控能力是一对矛盾,它们是大数据系统这块跷跷板的两端:
| 数据仓库 | 数据湖 | |
|---|---|---|
| 开放性 | 最差( lock in 厂商,读写数据一定要经过数据仓库) | 最好 |
| 掌控能力 | 最好(随意变换数据文件格式、调整数据分布) | 最差 |
Lakehouse 的贡献是找到了跷跷板的一个平衡点:
- 既通过对象存储和开源的列存格式提供了开放性;
- 又通过自研的数据访问协议保留了一定的数据掌控能力,从而为上层引擎优化(数据文件裁剪、Zorder 等)留下空间。
Delta Lake 的贡献是实现了一个开放的元数据系统、设计了一套访问元数据和数据的协议。
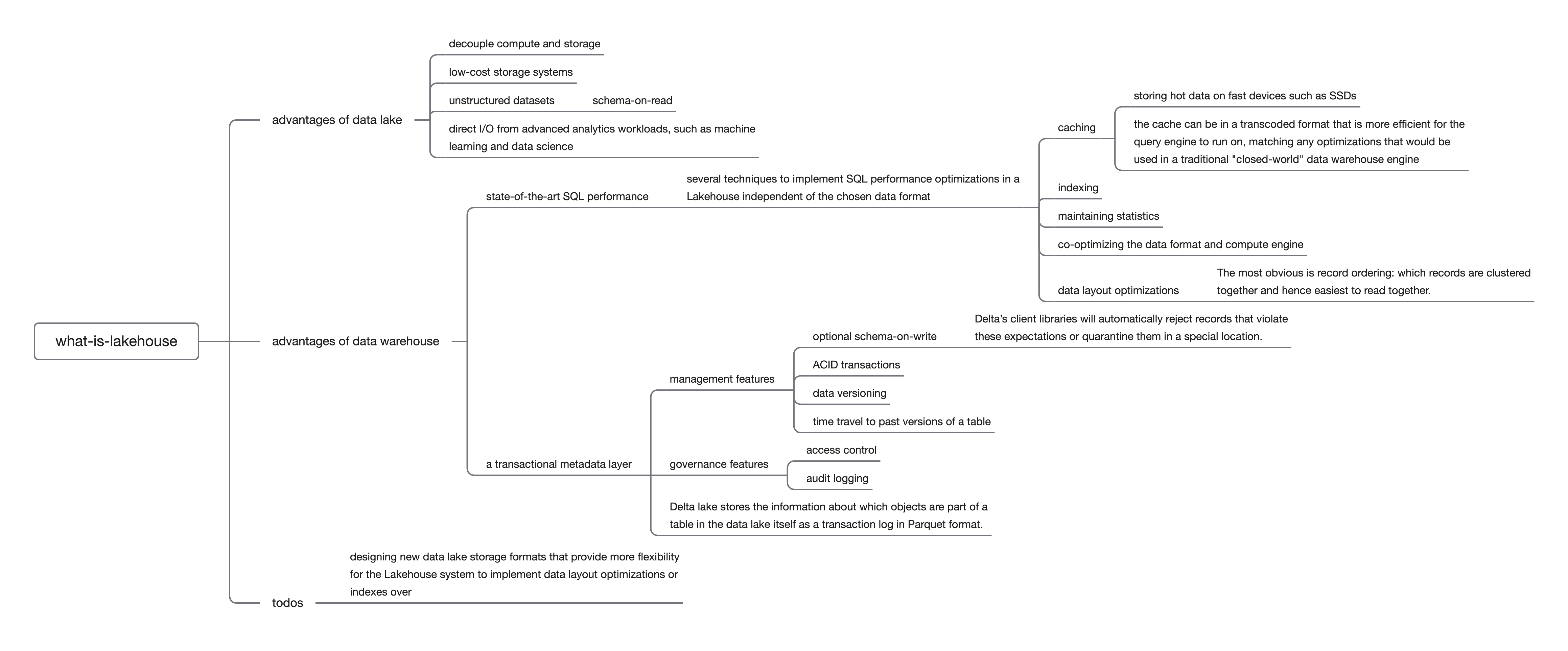
Delta Lake 的目标
Delta Lake 的目标是在开放性和对数据的掌控能力上取平衡点,兼得数据仓库和数据湖的优势,详细可查看幕布:
- 数据仓库凭借对数据的掌控能力能获得更多优化机会,理论上 SQL 性能比数据湖更好;由于其封闭性,更容易在存储层上架设元数据层,由元数据层提供 management 特性和 governance 特性。
- 数据湖则在成本和开放性上有优势。
Delta Lake 的架构
Delta Lake 的架构相较于 HDFS 有以下几点变化,详细可查看幕布:
- 由于对象存储不支持低成本的 rename 操作,需要由计算引擎配合存储层一起规避掉 rename 操作。
- 元数据以 transaction log 的形式存放在对象存储上,并依据对象存储的一些特性做适配;笔者认为用 RDS 存储元数据会在性能和易用性上都取得更好的成绩,也一一反驳了 Lakehouse 论文提出的、不将元数据存储到一个强一致系统的理由。
- 性能优化:并行读写数据和元数据、合理规划单个文件的大小、合并流式写入的小文件等。
Delta Lake 的目录结构:

参考资料
- Build Lakehouses with Delta Lake
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
- Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
- Cloudera Documentation: Introducing the S3A Committers
- 飞总聊 IT :DataBricks 新项目 Delta Lake 的深度分析和解读
- 知乎:深度对比 delta 、iceberg 和 hudi 三大开源数据湖方案
- 知乎:数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体
Delta Lake
https://clcanny.github.io/2021/05/23/computer-science/big-data/data-lake/delta-lake/