导读
Dynamic Linking: Symbol Search Order 介绍了在多个文件间查找符号的顺序,本篇文章会聚焦于 do_lookup_x 函数,探讨在单文件内查找符号的步骤:
布隆过滤器和哈希表是两个重要的数据结构;
它们是由编译器而不是运行时链接器准备的。
Hash sections 有两种格式,GNU hash section 和 SYSV hash section :
GNU hash section 比 SYSV hash section 具备更好的性能;
通过 -Wl,--hash-style=sysv 选项指定编译 SYSV hash section ;
通过 -Wl,--hash-style=gnu 选项指定编译 GNU hash section 。
本文讨论 GNU hash section 。
Code
加载 .gnu.hash section
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct link_map {const ElfW (Addr) * l_gnu_bitmask;union {const Elf32_Word* l_gnu_buckets;const Elf_Symndx* l_chain;union {const Elf32_Word* l_gnu_chain_zero;const Elf_Symndx* l_buckets;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void _dl_setup_hash(struct link_map* map ) {if (__glibc_likely(map ->l_info[ADDRIDX(DT_GNU_HASH)] != NULL )) {void *)D_PTR(map , l_info[ADDRIDX(DT_GNU_HASH)]);map ->l_nbuckets = *hash32++;1 )) == 0 );map ->l_gnu_bitmask_idxbits = bitmask_nwords - 1 ;map ->l_gnu_shift = *hash32++;map ->l_gnu_bitmask = (ElfW(Addr)*)hash32;32 * bitmask_nwords;map ->l_gnu_buckets = hash32;map ->l_nbuckets;map ->l_gnu_chain_zero = hash32 - symbias;return ;
从 GNU Hash ELF Sections 摘抄了一段关于 .gnu.hash section 的描述:
l_nbuckets The number of hash buckets
symbias The dynamic symbol table has dynsymcount symbols. symndx is the index of the first symbol in the dynamic symbol table that is to be accessible via the hash table. This implies that there are (dynsymcount - symndx ) symbols accessible via the hash table.
bitmask_nwords
The number of __ELF_NATIVE_CLASS sized words in the Bloom filter portion of the hash table section. This value must be non-zero, and must be a power of 2 as explained below.
Note that a value of 0 could be interpreted to mean that no Bloom filter is present in the hash section. However, the GNU linkers do not do this — the GNU hash section always includes at least 1 mask word.
l_gnu_shift A shift count used by the Bloom filter. HashValue_2 = HashValue_1 >> l_gnu_shift.
哈希算法
1 2 3 4 5 6 7 8 static uint_fast32_t dl_new_hash (const char *s) uint_fast32_t h = 5381 ;for (unsigned char c = *s; c != '\0' ; c = *++s)33 + c;return h & 0xffffffff ;
查找符号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 const struct link_map *map = list[i]->l_real;const ElfW (Addr) *bitmask if (__glibc_likely (bitmask != NULL ))ElfW (Addr) bitmask_wordunsigned int hashbit1 = new_hash & (__ELF_NATIVE_CLASS - 1 );unsigned int hashbit2 = ((new_hash >> map->l_gnu_shift)1 ));if (__glibc_unlikely ((bitmask_word >> hashbit1)1 ))if (bucket != 0 )const Elf32_Word *hasharr = &map->l_gnu_chain_zero[bucket];do if (((*hasharr ^ new_hash) >> 1 ) == 0 ) {check_match (undef_name, ref, version, flags,if (sym != NULL )goto found_it;while ((*hasharr++ & 1u ) == 0 );else
详解
.gnu.hash 需要有多个导出符号才能较方便地分析,因此我们将使用 test_gnu_hash.cpp 作为待分析的文件:
1 2 3 4 5 6 7 void foo () void bar () void test () void haha () void more ()
1 2 3
1 2 3 4 5
1 2 3 4 5 6 7
value
0x3
0x5
0x1
0x0
0x6
0x1801290804200400
[0x5, 0x8, 0x0]
[0xb8f7d29a, 0xb95a257a, 0xb9d35b69, 0x6a5ebc3c, 0x6a6128eb]
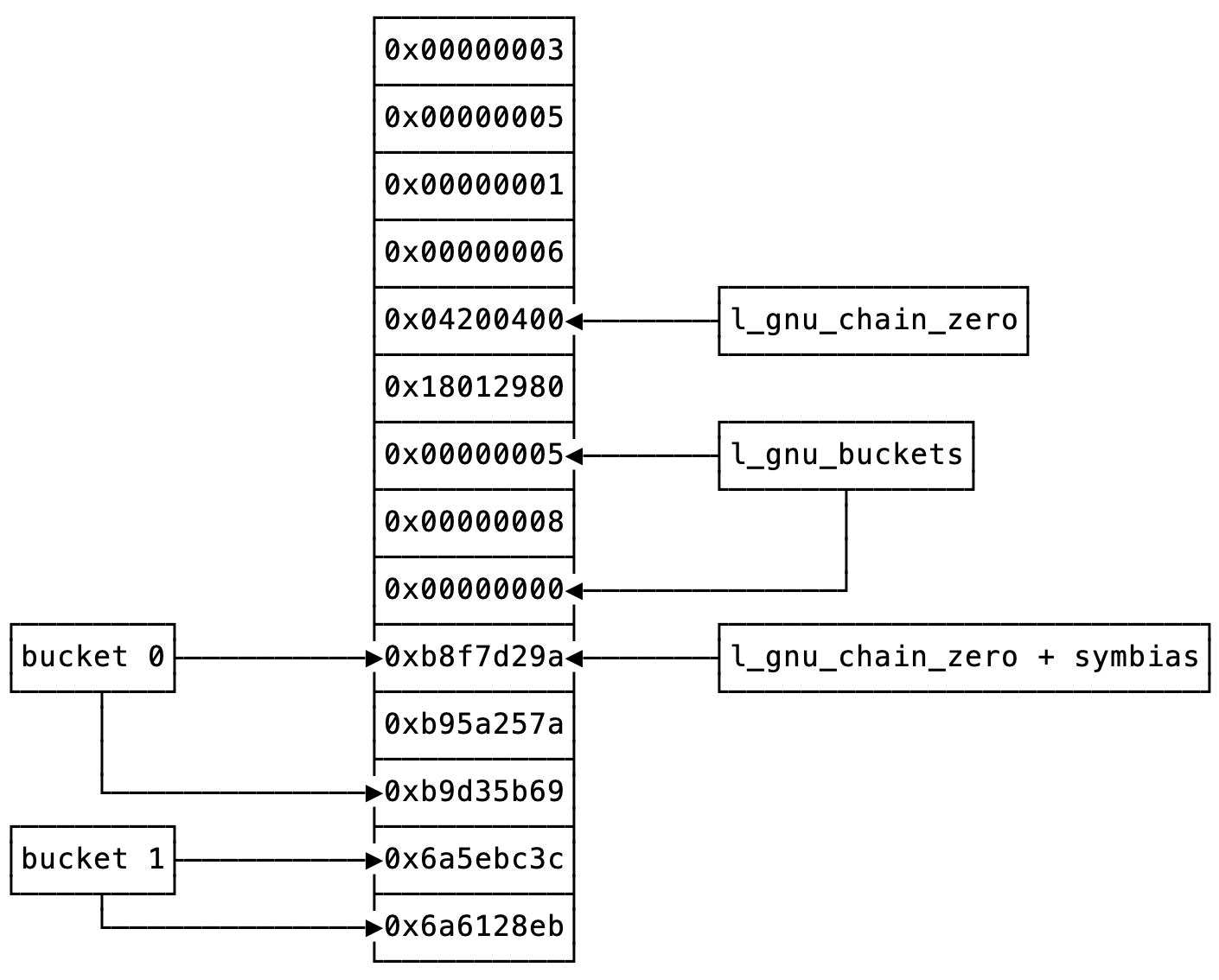
哈希表
编译器实现哈希表时用了几个技巧:
用一维数组 l_gnu_chain_zero + symbias 实现二维哈希表:
将在同一个哈希桶内的元素放在数组的连续区域;
用另一个一维数组 l_gnu_buckets 记录哈希桶的起始位置;
约定哈希桶的最后一个元素的最后一个比特是 1 ,其余元素的最后一个比特是 0 ;
为节省哈希表空间:
哈希表只记录哈希值,不记录符号在 .dynsym 表中的下标;
哈希表只记录可导出符号(比如 _Z3foov )的哈希值,不记录不可导出符号(比如 __cxa_finalize@GLIBC_2.2.5 )的哈希值;
为同时达到以上两个目标,编译器在 .dynsym 表中将不可导出符号(比如 __cxa_finalize@GLIBC_2.2.5 )排在可导出符号(比如 _Z3foov )的前面,将第一个可导出符号在 .dynsym 表中的下标记为 symbias ,计算 l_gnu_chain_zero 的公式是 map->l_gnu_chain_zero = map->l_gnu_buckets + map->l_nbuckets - symbias 。
因此,链接器查找哈希表的步骤是:
根据 l_gnu_buckets 找到哈希桶的第一个元素;
顺序搜索哈希桶内的元素,直到找到相应的哈希值或者到达结尾。
5
_Z4hahav
0xb8f7d29a
0xb8f7d29a
0
6
_Z4morev
0xb95a257b
0xb95a257a
0
7
_Z4testv
0xb9d35b68
0xb9d35b69 0
8
_Z3barv
0x6a5ebc3c
0x6a5ebc3c
1
9
_Z3foov
0x6a6128eb
0x6a6128eb 1
加粗部分是每个哈希桶的最后一个元素,最后一个比特需要置成 1 。
根据 l_gnu_buckets 找到哈希桶的第一个元素;
顺序搜索哈希桶内的元素,直到找到相应的哈希值或者到达结尾。
symbias
1 2 3 4 5 6 7 8 9 10 11 12 13 '.dynsym' contains 10 entries:
symbias 表明第一个可以通过 .gnu.hash section 访问的符号(即可以提供给其它库访问的符号),在 libtest_gnu_hash.so 中这个符号是 _Z4hahav 。
布隆过滤器
布隆过滤器的原理可以参考文章详解布隆过滤器的原理,使用场景和注意事项 ,简而言之,将数据使用多个不同的哈希函数生成多个哈希值,并将对应比特位置为 1 ,就能判断某个数据肯定不存在。
参考 GNU Hash ELF Sections ,构建布隆过滤器的伪代码如下:
1 2 3 4 5 6 7 8 const uint_fast32_t new_hash = dl_new_hash (undef_name);uint32_t H1 = new_hash;uint32_t H2 = new_hash >> map->l_gnu_shift;uint32_t N = (H1 / __ELF_NATIVE_CLASS) & map->l_gnu_bitmask_idxbits;unsigned int hashbit1 = H1 % __ELF_NATIVE_CLASS;unsigned int hashbit2 = H2 % __ELF_NATIVE_CLASS;1 << hashbit1);1 << hashbit2);
构建布隆过滤器的 C++ 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <ios> #include <iostream> uint32_t dl_new_hash (const char *s) uint32_t h = 5381 ;for (unsigned char c = *s; c != '\0' ; c = *++s)33 + c;return h & 0xffffffff ;const int __ELF_NATIVE_CLASS = 64 ;const int l_gnu_shift = 6 ;const int bitmask_nwords = 1 ;const int l_gnu_bitmask_idxbits = bitmask_nwords - 1 ;void new_bitmask (const char * s, uint64_t * bitmask_arr) uint32_t hash_value1 = dl_new_hash (s);uint32_t hash_value2 = hash_value1 >> l_gnu_shift;int n = (hash_value1 / __ELF_NATIVE_CLASS) & l_gnu_bitmask_idxbits;unsigned int hashbit1 = hash_value1 % __ELF_NATIVE_CLASS;unsigned int hashbit2 = hash_value2 % __ELF_NATIVE_CLASS;1L << hashbit1);1L << hashbit2);int main () uint64_t bitmask_arr[bitmask_nwords] = {0 };new_bitmask ("_Z4hahav" , bitmask_arr);new_bitmask ("_Z4morev" , bitmask_arr);new_bitmask ("_Z4testv" , bitmask_arr);new_bitmask ("_Z3barv" , bitmask_arr);new_bitmask ("_Z3foov" , bitmask_arr);"0x" << bitmask_arr[0 ] << std::endl;
More
编译器如何处理哈希冲突?
参考资料